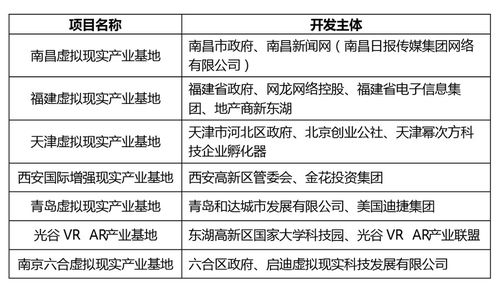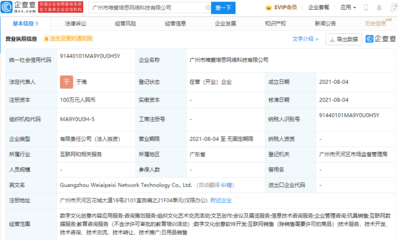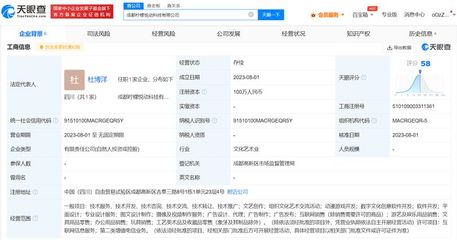
近日,備受玩家喜愛的《放置奇兵》研發商宣布正式成立一家專注于數字文化創意軟件開發的新公司。這一戰略性舉措標志著該公司在游戲開發領域之外,開始向更廣泛的數字文化創意產業拓展,展現了其在技術創新與文化傳播融合方面的雄心壯志。
新公司的成立將依托原有的技術積累和市場經驗,聚焦于開發具有文化內涵與創新交互體驗的軟件產品。這不僅包括游戲類應用,還將延伸至教育娛樂、數字藝術、虛擬展覽等多個領域,旨在通過數字化手段傳承與推廣優秀文化,同時為用戶帶來更豐富多元的互動體驗。
在數字經濟的浪潮下,文化創意產業與軟件開發的結合已成為新的增長點。該公司此舉順應了行業發展趨勢,有望在提升自身核心競爭力的同時,為整個數字文化生態注入新活力。未來,我們可以期待更多融合創意與技術的優質產品問世,進一步推動文化產業數字化升級。